It has been some time since I last posted a blog about SAP BusinessObjects. In part that was due to a lack of major changes in the SAP BusinessObject platform. A few Support Pack were released but there were only a handful of changes or enhancement that caught my attention. In addition to this, I am also excited to now be a part of the Protiviti family. In November of 2015, the assets of Decision First Technologies were mutually acquired by Protiviti. I am now acting as a Director within the Protiviti Data and Analytics practice. I look forward to all the benefits we can now offer our customers but unfortunately the acquisition transition required some of my time. Now that things are settling, I hope to focus more on my blogging. Now let’s get to the good parts…
With the release of SAP BusinessObjects 4.2 SP2, SAP has introduced a treasure trove of new enhancements. It contains a proverbial wish list of enhancements that have been desired for years. Much to my delight, SAP Web Intelligence has received several significant enhancements. Particularly in terms of its integration with SAP HANA. However, there were also enhancement to the platform itself. For example, there is now a recycling bin. Once enabled, user can accidentally delete a file and the administrator can save the day and recover the file. Note that there is a time limit or a configured number of days before the file is permanently deleted. Let’s take a more detailed look at my top 11 list of new features.
- Web Intelligence – Shared Elements
This is the starting point for something that I have always desired to see in Web Intelligence. For many years I have wanted a way to define a central report variable repository. While it’s not quite implemented the way I desired, within the shared elements feature, the end results is much the same. Hopefully they will take this a step further in the future but I can live with shared elements for now.
With that said, developers now have the option to publish report elements to a central located platform public folder. They can also refresh or re-sync these elements using the new shared elements panel within Webi. While this might not seem like an earth shattering enhancement, let’s take a moment to discuss how this works and one way we can use it to our advantage.
Take for example, a report table. Within that report table I have assigned a few key dimensions and measures. I have also assigned 5 report variables. These variables contain advanced calculations that are critical to the organization. When I publish this table to a shared elements folder, the table, dimensions, measures and variables are all published. That’s right, the variables are published too. Later on I can import this shared element into another report and all of the dimensions, measures and variables are also imported with the table. One important functionality note is that Web Intelligence will add a new query to support the shared elements containing universe objects. It does not add the required dimensions and measures to any existing query. This might complicate matters if you are only attempting to retrieve the variables. However, you can manually update your variable to support existing queries.
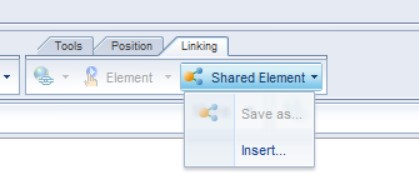
If you have not had the epiphany yet, let me help you out. As a best practice, we strive to maintain critical business logic in a central repository. This is one of many ways that we can achieve a single version of the truth. For the first time, we now have the ability to store Web Intelligence elements (including variables) in a central repository. Arguably, I still think it would be better to store variables within the Universe. However, shared elements are a good start. Assuming that developers can communicate and coordinate the use of shared elements, reports can now be increasingly more consistent throughout the organization.
I don’t want to underscore the other great benefits of shared elements. Variables are not the only benefit. Outside of variable, this is also an exceptional way for organization to implement a central repository of analytics. This means user can quickly import frequently utilized logos, charts and visualizations into their reports. Because the elements have all their constituent dependencies included, user will find this as an excellent way to simplify their self-service needs. I find it most fascinating in terms of charts or visual analytics. For the casual user they don’t need to focus on defining the queries, formats, and elements of the chart. They can simply import someone else’s work.
- Web Intelligence – Parallel Data Provider Refresh
I was quite pleasantly surprised that this enhancement was delivered in 4.2. In the past, Web Intelligence would execute each query defined in a report in serial. If there were four queries and each required 20 seconds to execute, the user would have to wait 4 x 20 seconds or 80 seconds for the results. When queries are executed in parallel, users only have to wait for the longest running query to complete. In my previous example, that means that report will refresh in 20 seconds not 80 seconds. Keep in mind that you can disabled this feature. This is something you might have to do if your database can not handle the extra concurrent workload. You can also increase or decrease the number of parallel queries to optimize your environment as needed.
- Web Intelligence – Geo Maps
Maps in Web Intelligence? Yes really, maps in Web Intelligence are no longer reserved for the mobile application. You can now create or view them in Web Intelligence desktop, browser or mobile. The feature also include a geo encoder engine. This engine allows you to geocode any city, state, country dimension within your existing dataset. Simply right click a dimension in the “Available Objects” panel to “Edit as Geography” A wizard will appear to help you geo encode the object. Note that the engine runs within an adaptive processing server and the feature will not work unless this service is running. I found this true even when using the desktop version of Web Intelligence.
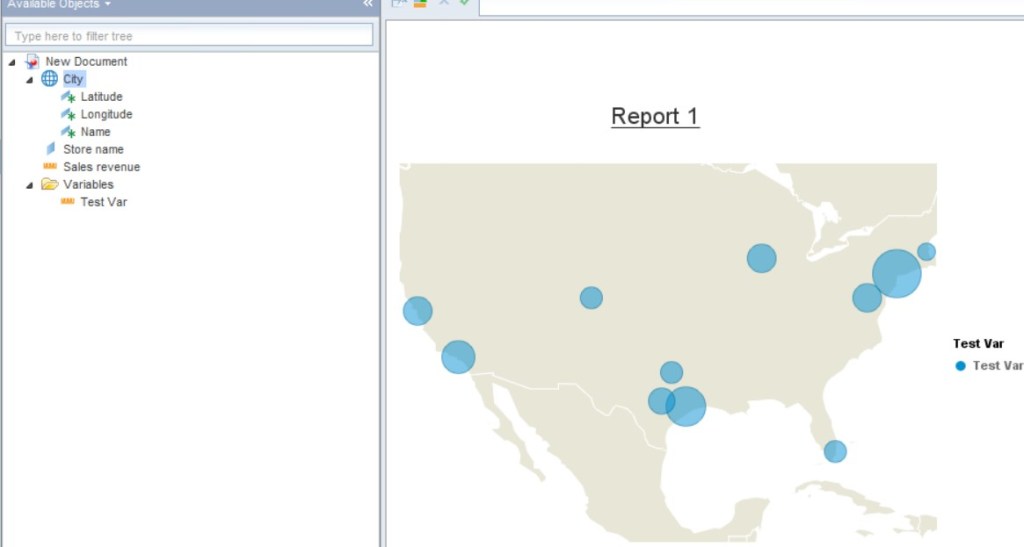
- Web Intelligence – Direct access to HANA views.
For those that did not like the idea of creating a Universe for each SAP HANA information view, 4.2 now allows the report developer to directly access a SAP HANA information view without the need to first create a universe. From what I can decipher, this option simply generates a universe on the fly.
However, it appears that metadata matters. The naming of objects is based on the label column names defined within SAP HANA. If you don’t have the label columns nicely defined, your available objects panel will look quite disorganized. In addition, objects are not organized into folders based on the attribute view or other shared object semantics. With that said, there is an option to organize dimension objects based on hierarchies defined in the HANA semantics. However, measures seem to be absent from this view in Web Intelligence (relational connections) which makes me scratch my head a little. Overall, I think it’s a great option but still just an option. If you want complete control over the semantics or how they will be presented within Web Intelligence, you still need to define a Universe.
- Web Intelligence – SAP HANA Online
Let me start by saying this, “this is not the same as direct access to HANA views”. While the workflow might appear to be similar, there is a profound difference in how the data is processed in SAP HANA online. For starters, the core data in this mode remains on HANA. Only the results of your visualization or table are actually transferred. In addition, report side filters appear to get pushed to SAP HANA. In other modes of connecting to HANA, only query level filters are pushed down. In summary, this option provides a self-service centered option that pushes many of the Web Intelligence data process features down to HANA.
As I discovered, there are some disadvantages to this option as well. Because we are not using the Web Intelligence data provider (micro cube) to store the data, calculation context functions are not supported. The same is true of any function that leverages the very mature and capable Web Intelligence reporting engine. Also, the semantics are once again an issue. For some reasons, the HANA team and Web Intelligence team can’t work together to properly display the Information view semantics in the available objects panel. Ironically, the semantics functionality was actually better in the 4.2 SP1 version than in the GA 4.2 SP2 release. In 4.1 SP1, the objects would be organized by attribute view (Same for Star Join calculation views). Webi would generate a folder for each attribute view and organize each column into the parent folder. In 4.2 SP2 we are back to a flat list of objects. In your model has a lot of objects, it will be hard to find them without searching. I’m not sure what’s going on with this, but they need to make improvements. For large models, there is no reason to present a flat list of objects.
Regardless of these few in number disadvantages, this is a really great feature. It truly has more advantages than disadvantages. User gain many of the formatting advantages of Webi while also leveraging the data scalability features of SAP HANA. As an added bonus, the report side filters and many other operations are pushed down to SAP HANA which makes reporting simple. User do not have to focus so intently on optimizing performance with prompts and input parameters.
We can finally link universes in IDT. UDT (Universe Design Tool) had this capability for many years. I am not sure why it was not included with IDT (Information Design Tool) from the beginning. That’s all I have to say about that…
- IDT – Authored BW BEx Universes
As proof that users know best, SAP relented and we can now define a Universe against a BEx query. No Java Connector or Data Federator required. This option uses the BICS Connection which offers the best performance. To me this all boils down to the need for better semantics integration. The same is also true of SAP HANA models. Having the ability to define a UNX universe on BEX queries has a lot to do with the presentation and organization of objects. For some strange reason users really care about the visual aspects of BI tools (and yes that last statement was sarcasm).
There are also option to change how measures are delegated. Measure that do not require delegation can be set to SUM aggregation. Fewer and fewer #ToRefresh# warnings I hope…
One of the more frustrating aspects of the platform over the last few decades was the inability to easily recover accidentally deleted items. In the past, such a recovery required 3rd party software or a side car restore of the environment. If you didn’t have 3rd party software or a backup, that deleted object was gone forever.
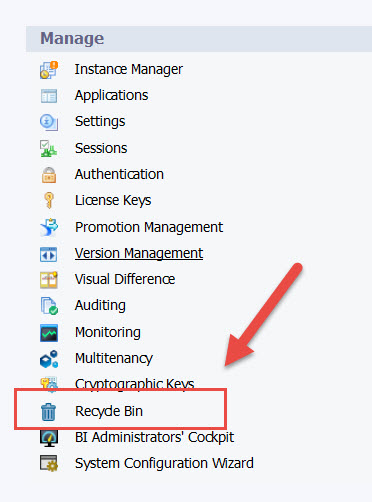
Once enabled, the Recycle Bin will allow administrators to recover deleted objects for a configurable amount of time. For example, we can choose to hold on to objects for 60 days. Only public folder content is support as well and user’s cannot recover objects without administrator help. However, this is a great first step and a feature that has been needed for over a decade.
Well it only took a few years but we can finally selectively import objects contained in an LCMBIAR file within the promotion management web application. Ironically I really wanted this functionality a few years ago to help with backups. Specifically public folder backup to aid users that accidentally deleted objects. Now that SAP designed the recycle bin, there is less of a need for this solution.
Prior to the latest enhancement, you had to import all objects in an LCMBIAR file. If I only wanted 1 of 8000 objects in the file, I had to import it into a dedicated temporary environment and then promote just the needed objects into the final environment.
- Platform – Split Installer
Using the installation command line, administrators can now prepare the system for installation without down time. It does this by performing all of the binary caching and some of the SQL lite installation database operations before it invokes the section of the install that require down time. Running setup.exe –cache will invoke the caching portions of the install. When ready to complete the install, running setup.exe –resume_after_cache will complete the insulation. In theory, the later portion of the installation step reduces the down time by eliminating the dependency between the two major installation and upgrade tasks.
In large clustered environment this is a great addition. In all types of environments this is a great enhancement. Previously the system down time was subjected to the long and tedious process of caching deployment units.
- Platform – New License Keys
After you upgrade to 4.2 SP2, you will need to obtain a new license keys. The keys that once worked for 4.0 and 4.1 will not work after upgrading to 4.2 SP2. The graphical installer will also let you know this. Be prepared to logon to service market place and request new keys.
More Information and links
I only mentioned what I thought to be the most interesting new features. However there are several other features including in 4.2 SP2. The following links contain more information about the new features in SAP BOBJ 4.2 SP2.
If you enjoyed this content, please share it!